GenAI in computer science education: Friend or foe?

Ask ChatGPT to generate a line of code for you, and it will, often with uncanny accuracy. Generative AI’s ability to create code and other content with surprising ease has given rise to widespread concerns about the danger of this technology in the classroom. Little is stopping students from relying on these platforms to complete assignments for them, rather than actually engaging with and learning the material. For many educators, in computer science and beyond, this has meant instituting a complete ban on GenAI for help with homework and projects, although methods to actually detect or regulate its use are often unreliable.
One instructor at the University of Michigan, teaching faculty and Associate Chair for Undergraduate Affairs Andrew DeOrio, is taking a different approach. Rather than fighting the AI revolution, he has decided to embrace it.
“A lot of the rhetoric right now is how to prevent students from using GenAI,” said DeOrio, “but what would happen if, instead, we told them to use it?”
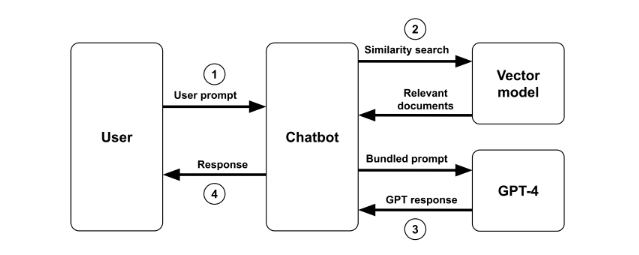
To explore GenAI’s potential as an educational aid, DeOrio and a team of teaching assistants in his EECS 485 Web Systems course, including Yutong Ai, Maya Baveja, Akanksha Girdhar, and Melina O’Dell, designed a chatbot using U-M’s Maizey AI toolkit. Rather than replacing traditional course materials or completing assignments for them, the goal was to train and deploy a chatbot that could augment existing resources and serve as a genuinely useful tool for students.

The team created a custom chatbot based on OpenAI’s GPT-4 architecture to help students as they worked on a project in small groups. For the assignment, students were tasked with designing a system using sockets, processes, and threads to run MapReduce parallel programs.
As DeOrio put it, “Say you are running a large website and need to crunch statistics on who is visiting your website. You might have too many log files for a standard computer program, so you would need a parallel program to read all of them. A MapReduce program can help you do that.”
DeOrio selected this type of assignment for the chatbot trial in part because of its complexity and open-endedness. He and his students wanted to create a tool that would not just generate answers, but could serve as a resource by helping to define concepts or explain project steps and goals. Building it around an advanced, multifaceted project like this one was part of that goal.
“While ChatGPT might excel at generating a line of basic code, when it comes to designing a complex framework such as this project entails, it falls short,” he said. “We wanted to design something that wouldn’t just give students easy answers but would instead facilitate their learning.”
DeOrio and his students trained the bot using course materials related to the project, including lecture PDFs and transcripts, tutorials, the project specification, and Piazza forum posts related to the project from previous semesters. He then deployed the bot to the more than 700 students in EECS 485 and asked them to use it at least three times as they worked on the project.
The results of this trial were encouraging, to say the least. In a survey completed by almost 300 student groups after completing the project, respondents reported that the majority (77%) of their interactions with the GenAI chatbot were helpful.
The team also found that students made use of the chatbot more than expected. While they were required to use the bot at least three times, the average number of interactions was 4-10 per group, with some using it a dozen times or more.
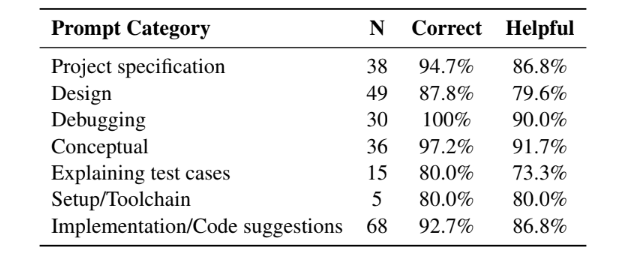
This rate of use on a single project indicates that the chatbot provided students with useful information as they worked on the assignment. In particular, students reported that the bot performed best when answering questions related to concepts and project specifications, while being less reliable in explaining test cases relevant to the project.
The survey responses reflect this:
- “I found it very helpful, it was succinct and answered my question exactly as I had hoped,” said one student, after asking the bot to provide a conceptual explanation.
- According to another student, the chatbot was “very helpful at providing background context for concepts in code we weren’t familiar with [and] good for syntax errors or odd/specific configurations that we weren’t used to.” This same student noted that the bot was “not a replacement for coding,” but that “it was overall incredibly useful, especially for debugging.”
- Another respondent reported, “It gave us helpful clarification on the spec and helped with debugging. Having a similar bot for other projects would be helpful.”
A big concern of DeOrio and his student team was accuracy, particularly considering GenAI’s troubling tendency to “hallucinate,” that is, to generate false or misleading information and present it as fact. This is especially concerning in an educational setting, where misinformation could interfere with student learning.
Fortunately, the bot that DeOrio and his students designed was surprisingly accurate. Upon instructor review, the team found that 92% of the chatbot’s responses were correct. And, interestingly, of the 8% incorrect answers provided by the chatbot, students were able to identify them as incorrect over 96% of the time.
“While the goal is to build as robust and accurate a tool as possible,” said DeOrio, “even in this early iteration, only a very small percentage of chatbot mistakes were able to slip through the cracks.”
Also promising is the custom chatbot’s efficacy compared to a general purpose bot, in this case ChatGPT. DeOrio and his team found that their chatbot outperformed ChatGPT on several fronts, providing more detailed and relevant responses that directly related to the project specifications, whereas ChatGPT’s answers were more generic.
While survey results clearly demonstrated the utility of the chatbot, most students reported that they still preferred interacting with instructors directly via office hours or on the course forum on Piazza.
To DeOrio, however, this is actually an encouraging sign. “It shows that students aren’t using the bot to replace traditional learning avenues, but to augment the resources they already have,” he said.
With undergraduate enrollment and class sizes booming and teaching capacity stretched thin across the computer science discipline, any resource that can further enhance learning and support students is a welcome addition.
For DeOrio, the positive results of his group’s chatbot trial give him hope for the future of GenAI in computer science education. “GenAI is another way for students to get feedback on their work that is quick and low stakes,” he said. “Based on the feedback we’ve received in this early iteration, I think this kind of tool has great potential.”
Going forward, DeOrio plans to continue to explore and refine GenAI tools to support student learning, starting with an expansion of the current version of his course chatbot. “We hope to expand the scope of our bot to cover the whole class to see if it continues to be useful,” he said.
Another challenge to address going forward is whether a similar tool could be designed for lower-level classes, where GenAI could provide easy answers for more straightforward coding questions. “We want to avoid the pitfall of students asking the bot to just do their homework for them,” said DeOrio.
By demonstrating AI as a useful educational aid rather than a shortcut to answers, DeOrio’s experiment offers a glimpse into a future where AI can be successfully integrated into the classroom. As educators and institutions grapple with the challenges and opportunities presented by GenAI, the success of this experiment serves as a testament to its potential benefits, when harnessed correctly, in supporting future generations of computer scientists.